Tratamento de Dados no RH: como funciona e quais os principais desafios?
Conheça os principais desafios de tratamento de dados no RH e entenda como superá-los escolhendo o modelo ideal para o analytics da sua organização
Texto escrito por: Rafael de Melo Balaniuk e revisado por Thuany Gibertini
Em qualquer análise de dados, a confiabilidade é fundamental. Em outras palavras, se a informação que entra não é correta, não há análise no mundo que a corrija. Podemos resumir isso na frase famosa de George Fuechsel, técnico da IBM: “entra lixo, sai lixo”.
Sendo assim, um dos grandes desafios do RH data-driven começa na coleta e priorização dos dados que entrarão para sua análise. Então, antes de irmos para o analytics avançado, que é a parte mais popular do people analytics, vamos falar um pouco de tratamento de dados.
Como garantir que o RH tem as informações corretas?
O desafio de RH de ter bons dados não é simples. Segundo relatório produzido pela Josh Bersin Academy, os RHs usam, em média, 20 a 30 fontes de dados diferentes. Esses dados vêm de diferentes fontes:
- Plataformas internas estruturadas, como os ERPs (Sistema Integrado de Gestão Empresarial) . Por exemplo, RM da TOTVS, SAP, entre outras;
- Pesquisas internas, como de clima, avaliação de desempenho, avaliações 360°,etc;
- Planilhas internas, como planilha de acompanhamento de vagas de R&S;
- Plataformas externas, por exemplo, R&S, avaliação de desempenho ou clima.
Integrar todas essas informações é complexo, principalmente quando o RH interno não é o dono do dado, como acontece no caso das plataformas externas.
E o desafio não acaba quando os dados são integrados. Cada uma das fontes tem inúmeros campos. Você já parou para pensar em quantos campos existem no seu ERP? Para criar bons indicadores, é necessário escolher a forma ideal de cruzamento dos dados que representa o conceito do indicador.
Por exemplo, imagine que você quer saber qual é o grau de facilidade para contratar pessoas de um determinado cargo na sua empresa. Como indicador, você adota a quantidade de candidatos às vagas que você abre para esse determinado cargo.
Isso é um erro porque esse indicador não tem a informação que você busca. Pode ser que muitos profissionais se candidatem para a vaga, mas que quase todos sejam inadequados . Nesse caso, seu indicador aponta que é um cargo fácil de contratar, mas não é.
Veja um exemplo fictício, que ilustra esse problema da escolha correta dos campos:
Imagine que você queira contar quantos funcionários ativos havia no dia 10 de um determinado mês. Para isso, você puxou um relatório de funcionários do mês e usou os campos de status e de data de desligamento. A fórmula que você usou foi:
nº de funcionários com o status ativo
+
nº de funcionários com o status de desligado com data posterior ao dia 10
Faz sentido, não? Mas você encontrou que havia uma diferença de dez pessoas para o número real, o que representa 0,1% do quadro. Quando foi olhar a fundo, viu os seguintes problemas:
- Alguns desligados antes do dia 10 estavam como ativos. Isso aconteceu porque o sistema calculou o status considerando o primeiro dia útil do mês;
- Alguns admitidos depois do primeiro dia útil do mês não estavam na lista, devido ao mesmo problema;.
- Alguns ativos estavam com o status de desligado. Isso aconteceu porque sua empresa é um conglomerado e às vezes você precisa trocar colaboradores entre as empresas do conglomerado. Para fazer isso, você precisou desligá-los em uma empresa e admiti-los em outra. Ao fazer isso, o sistema puxou o status desses colaboradores como desligado.
Nesse caso, como a referência é um dia específico, o modelo ideal a ser usado é a combinação da tabela de colaboradores com as tabelas de eventos (lista de admissões e demissões realizadas no mês).
Isso porque apenas no formato de eventos é possível identificar quando os colaboradores são movimentados mais de uma vez e esses múltiplos registros permitem que seja feita uma reconstrução diária de quem estava ativo na empresa.
Em suma, mesmo calcular a quantidade de ativos, que parece uma atividade trivial, pode levar a erros se as tabelas corretas não forem usadas. Quando há erros nos números apresentados, toda a área de RH perde a confiança da diretoria.
Isso porque o maior medo de um gestor, quando lida com dados, é que o indicador esteja incorreto. Se ele não tiver confiança no número apresentado, vai abandonar o indicador e tomar decisões baseadas na intuição.
Mas então, como garantir o tratamento correto dos dados no RH?
A melhor forma de garantir um bom tratamento de dados no RH é unir o conhecimento especializado de RH com o conhecimento de dados. Assim, é preciso ter profissionais das duas áreas analisando os dados juntos e criando uma rotina que considere as particularidades para que não haja erros.
Qual o modelo de tratamento de dados ideal para o RH?
Não é comum que RHs conheçam modelos de dados, essa tarefa geralmente fica para a equipe de TI. Assim, incubida dessa tarefa, o TI segue uma linha mestra: dar cada vez mais autonomia para as áreas-fim.
Ou seja, para não ser demandada constantemente, a área de tecnologia usa ferramentas mais genéricas e user-friendly que permitem que o usuário faça o que ela fazia anteriormente.
Isso é uma ótima prática porque os profissionais de negócio podem até não entender de modelos de dados, mas entendem o problema do negócio. Como conhecem o problema, são os mais indicados para resolvê-lo.
Um bom exemplo dessa prática é o BI, que foi uma ferramenta criada nos anos de 1970 para possibilitar o aprofundamento da análise de dados de um problema pelos gestores.
O mesmo acontece com o cruzamento de dados, sendo que o RH está transitando de data warehouses para data lakes.
Mas vamos voltar um pouco…
O que são data warehouses (DW)?
Em termos simples, é uma estrutura com dados relacionados onde todos os números e os relacionamentos já foram predefinidos. Esses dados são usados por aplicações de business intelligence para ajudar na tomada de decisão.
O ponto positivo desse modelo é que, por tudo ser montado por um especialista em dados, há poucos erros. O ponto negativo é o alto custo do data warehouses, já que qualquer novo dado ou nova ligação deve ser feita pelo especialista.
De acordo com um artigo produzido pelo GEGIT (Grupo de Estudos em gestão, Inovação e Tecnologia) da UFCG (Universidade Federal de Campina Grande), a definição formal de data warehouse é:
— “DW é um repositório de informações coletadas em diversas fontes, armazenadas sob um esquema único, em um só local. Uma vez coletados, os dados são armazenados por um período longo, permitindo acesso a dados históricos”.
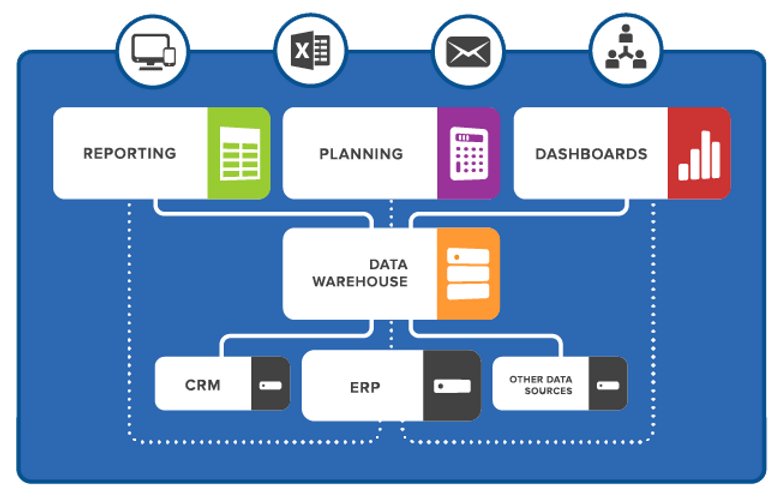
Crédito da imagem: Reprodução
Os data warehouses são:
- Orientados por assunto – referindo-se aos assuntos de interesse da empresa;
- Integrados – trazendo os dados originais dos sistemas operacionais para que estes tenham um sentido singular;
- Variantes no tempo – salientando que os dados sempre apresentam uma característica de tempo, ou seja, a cada mudança ocorrida num dado, uma nova entrada é criada e não atualizada;
- Não volátil – destacando que os dados não recebem atualizações, eles são carregados uma única vez e, a partir desse momento, só podem ser consultados;
O que são data lakes?
Em termos simples, data lakes são grandes repositórios de dados tratados ou não (estruturados, semiestruturados e não estruturados), que podem ser relacionados pelos usuários.
Os pontos positivos são a escalabilidade, o custo e as possibilidade de novos insights. O usuário tem autonomia para manipular todos os dados que estão no repositório.
Os pontos negativos são a dificuldade de manter esse repositório, garantindo que não tenha dados de baixa qualidade e vire um “pântano” e a possibilidade do usuário fazer cruzamentos errados.
Por exemplo, o usuário pode confundir os campos de código do colaborador em dois sistemas diferentes, fazer a ligação e gerar uma grande quantidade de dados nulos. Esse modelo exige que o usuário tenha um conhecimento intermediário de manipulação de dados e do tema ao qual os dados se referem.
Histórico de repositórios de dados no RH
Cada vez mais o RH busca usar dados para tomar decisões em relação a pessoas. Não só os dados ganharam mais importância como as fontes de dados aumentaram, aponta um artigo da TechTarget.
Um artigo científico escrito por mim, Rafael de Melo Balaniuk, em conjunto com Jairo Eduardo Borges Andrade, aponta quais dados são coletados e analisados pelas organizações atualmente:
— “Hoje, as empresas de ponta continuam analisando os dados tradicionais (remuneração, benefícios, desligamentos, clima organizacional, entre outros) e buscam cruzá-los com dados comportamentais brutos (e-mails corporativos, microexpressões faciais em processos seletivos, acesso a páginas de internet, movimento do mouse).”
A análise desses dados brutos passou a ser considerada uma necessidade nas multinacionais que são referências de mercado, de acordo com um artigo da Harvard Business Review. É inviável estruturar esses dados em formato de data warehouse.
Para que seja possível analisar esse tipo de dados e cruzá-los com os dados tradicionais, que temos em ERPs, questionários e outros, essas empresas precisam transitar dos data warehouses para os data lakes.
Essa tendência chegou ao Brasil e algumas empresas de grande porte estão adotando os data lakes, mesmo sendo muito raro que empresas brasileiras usem os dados brutos.
Qual é o impacto de usar data lakes no RH?
A princípio, parece não haver nenhum risco nisso, uma vez que os data lakes armazenam tanto os dados brutos (não estruturados) quanto os tratados (estruturados). No entanto, essa prática pode diminuir a qualidade dos indicadores.
Isso pode acontecer por dois motivos: o primeiro deles é que um dos maiores gaps de competências dos profissionais de RH é a análise de dados; o segundo é que profissionais especializados em dados dificilmente têm conhecimento aprofundado em RH.
Isso é um problema porque os dados da área de gestão de pessoas estão entre os mais complexos de serem analisados. Uma vez que vêm de múltiplas fontes e os conceitos são de naturezas muito variadas, indo desde engajamento (dado soft) até salário (dado duro).
Ou seja, conectar dados e criar bons indicadores de recursos humanos não é fácil nem para os analistas de RH, que em geral conhecem pouco de dados, nem para os especialistas em dados, que conhecem pouco de recursos humanos.
Pode parecer que esse problema se aplica apenas a indicadores complexos, mas se aplica até ao mais corriqueiro deles, como a quantidade de colaboradores ativos.
Qual é o impacto de usar data warehouses no RH?
Com os data warehouses, existe a demanda para que toda a estrutura de dados seja montada já com suas respectivas conexões. Assim, os profissionais de recursos humanos e dados constroem, em conjunto, a melhor forma de tratar os dados e calcular os indicadores.
Voltando ao exemplo da contabilização de colaboradores ativos. Antes dos data lakes, o RH apontava as fases do processo de admissão e as regras de negócio, enquanto que dados apontavam as melhores formas de traduzir o processo em dados e juntos eles definiam um procedimento de extração, tratamento e cálculo.
Esse procedimento era replicado para todos os cálculos de ativos que a empresa realizasse e o risco de erro era mínimo. Hoje, é obrigatório enviar a quantidade de ativos para a Secretaria de Trabalho pelo e-social. Existe uma forma padronizada de tratar e categorizar esses dados.
Ainda assim, as informações que vão para o e-social e que vão para os indicadores de RH não necessariamente são as mesmas. Por isso, o fato de os ERPs enviarem dados para o e-social não é, por si só, garantia de indicadores corretos.
Como resolver o problema?
A solução do problema não é abandonar o novo, mas sim aproveitar os pontos positivos de cada solução. Ela é a seguinte:
Construir o racional de um banco de dados relacional (figura abaixo) no modelo de um data warehouse e usar essa estrutura no repositório que a empresa já tem (data warehouse ou data lake).
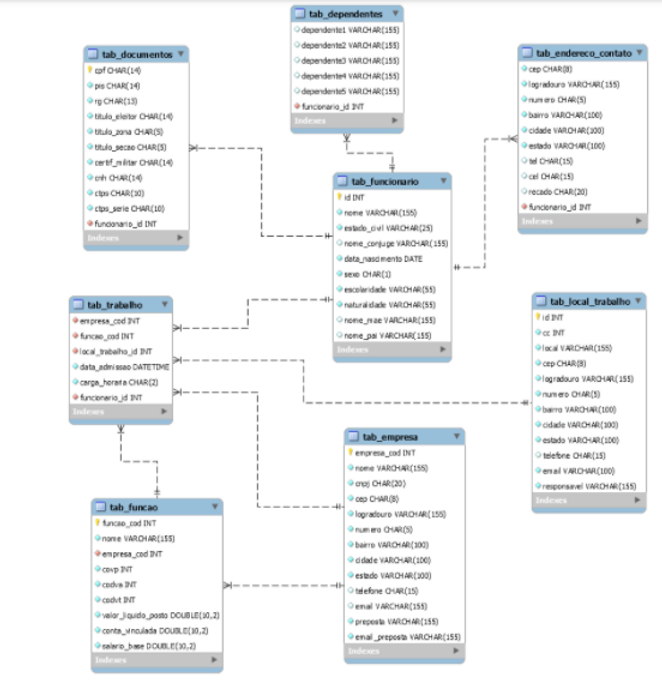
Crédito da imagem: Reprodução Stack Overflow
Assim, é possível ter a flexibilidade de um data lake com a confiabilidade de um data warehouse.
Com esse tipo de solução, é possível levar aos tomadores de decisão os dados que eles precisam em tempo real e de forma confiável. Eles permitem a construção de dashboards, por analistas de RH e de negócio, cruzando dados de todos os subsistemas da área de recursos humanos.
A Salt RH é a solução para o tratamento de dados no RH da sua organização
Nós, da Salt RH, mapeamos os dados e dores de RH e construímos uma estrutura de DW que serve para calcular indicadores sem erros e sem trabalho operacional. Nossos indicadores também são flexíveis, para que seja possível traduzir os conceitos do seu negócio.
A Salt RH pode te ajudar na implementação do People Analytics na sua empresa. Da adoção do people analytics aos modelos preditivos mais avançados, levamos tecnologia, estatística e gestão de pessoas para trabalhar a favor do seu negócio. Entre em contato conosco!
Gostou deste artigo sobre os principais desafios de tratamento de dados no RH? Compartilhe com a sua rede e acompanhe mais conteúdos como este em nosso blog e nos siga nas redes sociais.
*Crédito da foto destacada:
#datawarehouses #rhtech #RHedados #datalakes #hranalytics #PeopleAnalytics